Contains one row for every row in CENSUS. Each row contains the CENSUS columns and the related DEMOG columns. In those cases where there is a
CENSUS row but no related DEMOG row the DEMOG columns will
be NULL. Because there is a one-to-one relationship between
CENSUS and DEMOG, and a
DEMOG row always has a related CENSUS row, there is little utility in maintaining
the DEMOG row without maintaining the
related CENSUS row. This view provides a
convenient way to maintain the CENSUS/DEMOG combination.
Figure 6.1. Query Defining the CENSUS_DEMOG View
SELECT census.cenid AS cenid
, census.sname AS sname
, census.date AS date
, census.grp AS grp
, census.status AS status
, census.cen AS cen
, demog.reference AS reference
, demog.comment AS comment
FROM census LEFT OUTER JOIN demog ON (census.cenid = demog.cenid);
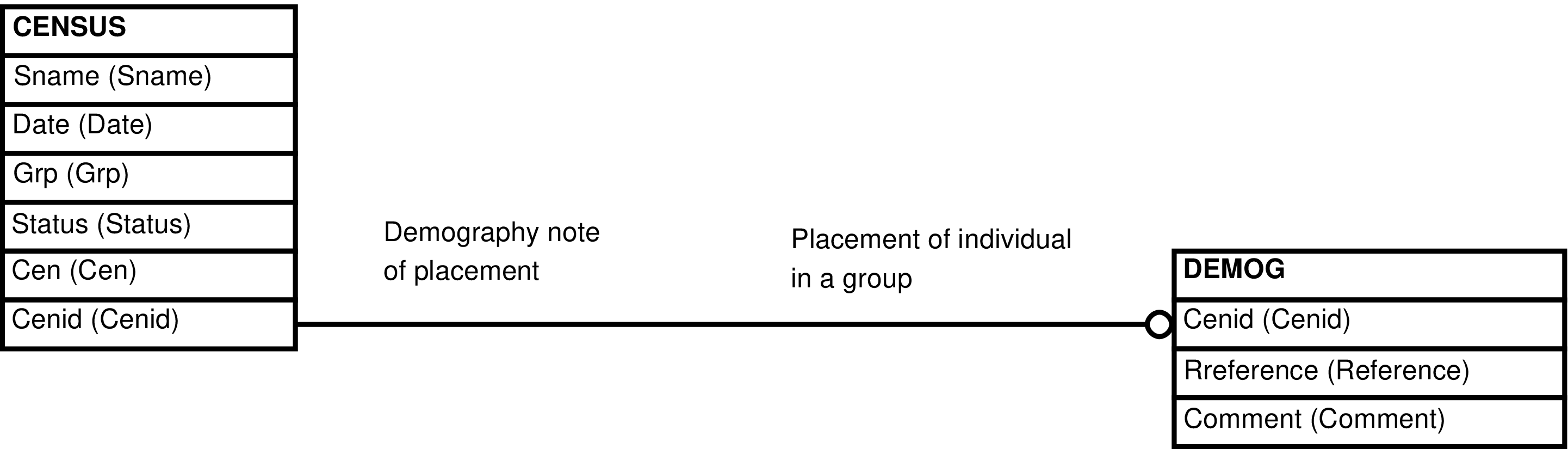
Table 6.1. Columns in the CENSUS_DEMOG View
| Column | From | Description |
|---|---|---|
| Cenid | CENSUS.Cenid | Unique identifier of the CENSUS row. |
| Sname | CENSUS.Sname | Individual who's location has been recorded. |
| Date | CENSUS.Date | Date of demography note. |
| Grp | CENSUS.Grp | Group where the individual was located. |
| Status | CENSUS.Status | Source of location information. When the source is both a demography note and another source, like a census, the other source is shown. |
| Cen | CENSUS.Cen | Whether or not there was an entry on the field census data sheet for the individual on the given date. |
| Reference | DEMOG.Reference | The group identifying the written field notebook where the demography note can be found. |
| Comment | DEMOG.Comment | The demography note text. |
Inserting a row into CENSUS_DEMOG inserts two rows,
one into CENSUS and one into DEMOG, as expected. However, if the
underlying DEMOG columns are NULL, no
DEMOG row will be inserted.
Warning
The PostgreSQL nextval()
function cannot be part of an INSERT
expression which assigns a value to this view's Cenid
column.
Updating a row in CENSUS_DEMOG updates the underlying columns in CENSUS and DEMOG, as expected. However, the relationship between CENSUS and DEMOG introduces some complications.
Caution
The CENSUS table is updated before the DEMOG table. Because updating the DEMOG table can change the CENSUS.Status column the resulting value may not be that specified by the update.
Updating the Cenid column updates[247] the Cenid columns in both CENSUS and DEMOG. Setting
all the DEMOG columns (Cenid excepted) to NULL causes the
deletion of the DEMOG row. Setting
DEMOG columns to a non-NULL value
when all the DEMOG columns were NULL
previously creates a new row in DEMOG.
Caution
The CENSUS-DEMOG view cannot be used to delete arbitrary CENSUS rows.
Deleting rows from CENSUS_DEMOG updates the database in a fashion that removes the related demography note information from storage.
Deleting a row in CENSUS_DEMOG deletes the
underlying row in CENSUS when
appropriate; when the CENSUS row exists
only because there is an underlying row in DEMOG. That is, the CENSUS
row is deleted if and only if the CENSUS.Cen column is
FALSE. If there is an underlying row in DEMOG it is always deleted.
Contains one row for every row in the CENSUS_DEMOG view. The only difference between this view and the CENSUS_DEMOG view is that this view is sorted.
Figure 6.3. Query Defining the CENSUS_DEMOG_SORTED View
SELECT census.cenid AS cenid
, census.sname AS sname
, census.date AS date
, census.grp AS grp
, census.status AS status
, census.cen AS cen
, demog.reference AS reference
, demog.comment AS comment
FROM census LEFT OUTER JOIN demog ON (census.cenid = demog.cenid)
ORDER BY census.sname, census.date;
Table 6.2. Columns in the CENSUS_DEMOG_SORTED View
| Column | From | Description |
|---|---|---|
| Cenid | CENSUS.Cenid | Unique identifier of the CENSUS row. |
| Sname | CENSUS.Sname | Individual who's location has been recorded. |
| Date | CENSUS.Date | Date of demography note. |
| Grp | CENSUS.Grp | Group where the individual was located. |
| Status | CENSUS.Status | Source of location information. When the source is both a demography note and another source, like a census, the other source is shown. |
| Cen | CENSUS.Cen | Whether or not there was an entry on the field census data sheet for the individual on the given date. |
| Reference | DEMOG.Reference | The group identifying the written field notebook where the demography note can be found. |
| Comment | DEMOG.Comment | The demography note text. |
The operations allowed are as described in the CENSUS_DEMOG view.
Contains one row for every row in CYCPOINTS. Each row contains the CYCPOINTS columns and the related CYCLES columns. Because there is a many-to-one relationship between CYCPOINTS and CYCLES, the same CYCLES data will appear repeatedly, once for each related CYCPOINTS row. As a CYCPOINTS row always has a related CYCLES row, and the CYCLES row is what identifies the cycling female, when working with the CYCPOINTS table alone it is difficult to tell which dates belong to which females. This view provides a convenient way to create and maintain the CYCPOINTS/CYCLES combination.
Figure 6.5. Query Defining the CYCPOINTS_CYCLES View
SELECT cycles.cid AS cid
, cycles.sname AS sname
, cycles.seq AS seq
, cycles.series AS series
, cycpoints.cpid AS cpid
, cycpoints.date AS date
, cycpoints.edate AS edate
, cycpoints.ldate AS ldate
, cycpoints.code AS code
, cycpoints.source AS source
FROM cycles, cycpoints
WHERE cycles.cid = cycpoints.cid;
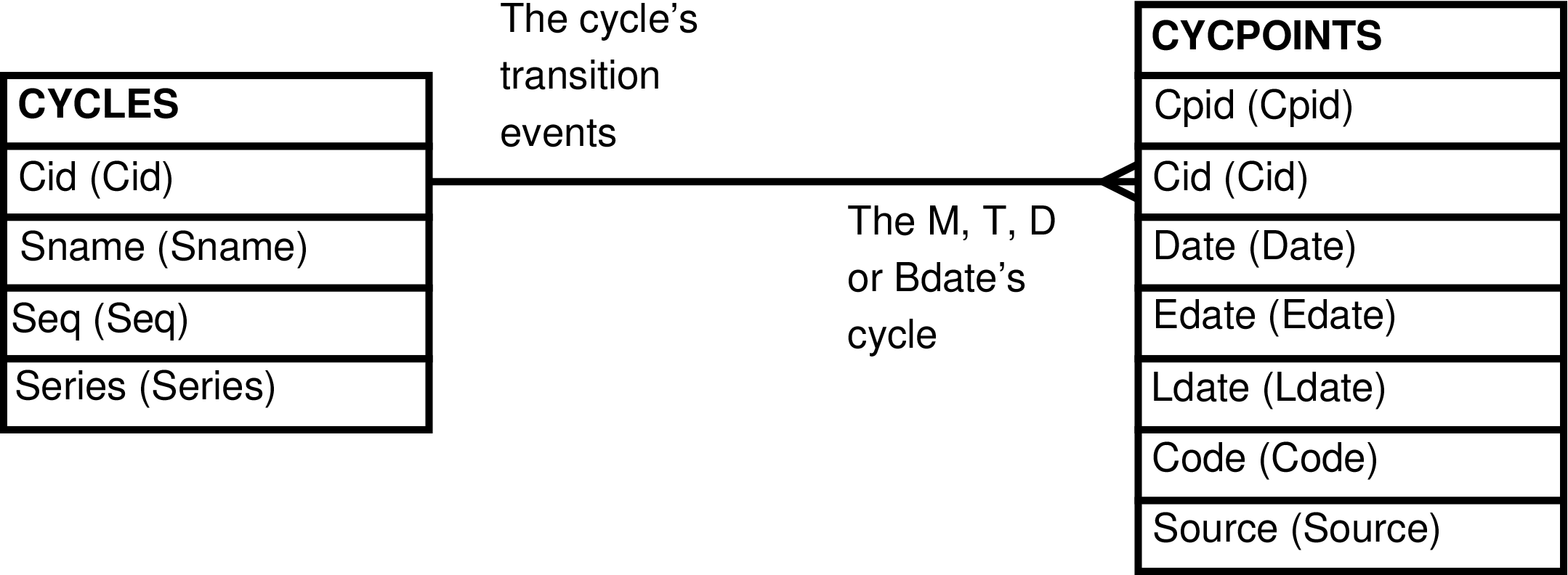
Table 6.3. Columns in the CYCPOINTS_CYCLES View
| Column | From | Description |
|---|---|---|
| Cid | CYCLES.Cid | Arbitrary number uniquely identifying the CYCLES row. |
| Sname | CYCLES.Sname | Female that is cycling. |
| Seq | CYCLES.Seq (readonly) | Number indicating the cycle's position in time within the sequence of all the cycles of the female. Counts from 1 upwards. |
| Series | CYCLES.Series (readonly) | Number indicating with which CYCLES (Female Sexual Cycles) of continuous observation the cycle belongs. |
| Cpid | CYCPOINTS.Cpid | Number uniquely identifying the CYCPOINTS row. |
| Date | CYCPOINTS.Date | Date-of-record of the sexual cycle transition event. |
| Edate | CYCPOINTS.Edate | Earliest possible date for the sexual cycle transition event. |
| Ldate | CYCPOINTS.Ldate | Latest possible date for the sexual cycle transition event. |
| Code | CYCPOINTS.Code | The type of sexual cycle transition event. Mdate, Tdate, or Ddate. |
| Source | CYCPOINTS.Source | Code indicating from whence the data was derived. This has a bearing as to its accuracy. |
Tip
In most cases Cid, Cpid, Seq, and Series should be
unspecified (or specified as NULL), in which case Babase
will compute and assign the correct values.
Inserting a row into CYCPOINTS_CYCLES inserts a row into CYCPOINTS, as expected. Whether or not a row is inserted into CYCLES depends on whether or not the new CYCPOINTS row should be associated with a new CYCLES row or an existing one. When a Cid is supplied and a CYCLES row already exists with the given Cid then the underlying CYCLES row is updated to conform with the inserted data. When a Cid is supplied and Babase finds that the underlying CYCPOINTS row should be related to a CYCLES row with a different Cid the system silently ignores the supplied Cid.
Contains one row for every row in the CYCPOINTS_CYCLES view. This view is sorted for ease of maintenance.
Figure 6.7. Query Defining the CYCPOINTS_CYCLES_SORTED View
SELECT cycles.cid AS cid
, cycles.sname AS sname
, cycles.seq AS seq
, cycles.series AS series
, cycpoints.cpid AS cpid
, cycpoints.date AS date
, cycpoints.edate AS edate
, cycpoints.ldate AS ldate
, cycpoints.code AS code
, cycpoints.source AS source
FROM cycles, cycpoints
WHERE cycles.cid = cycpoints.cid
ORDER BY cycles.sname, cycpoints.date;
Table 6.4. Columns in the CYCPOINTS_CYCLES_SORTED View
| Column | From | Description |
|---|---|---|
| Cid | CYCLES.Cid | Arbitrary number uniquely identifying the CYCLES row. |
| Sname | CYCLES.Sname | Female that is cycling. |
| Seq | CYCLES.Seq (readonly) | Number indicating the cycle's position in time within the sequence of all the cycles of the female. Counts from 1 upwards. |
| Series | CYCLES.Series (readonly) | Number indicating with which CYCLES (Female Sexual Cycles) of continuous observation the cycle belongs. |
| Cpid | CYCPOINTS.Cpid | Number uniquely identifying the CYCPOINTS row. |
| Date | CYCPOINTS.Date | Date-of-record of the sexual cycle transition event. |
| Edate | CYCPOINTS.Edate | Earliest possible date for the sexual cycle transition event. |
| Ldate | CYCPOINTS.Ldate | Latest possible date for the sexual cycle transition event. |
| Code | CYCPOINTS.Code | The type of sexual cycle transition event. Mdate, Tdate, or Ddate. |
| Source | CYCPOINTS.Source | Code indicating from whence the data was derived. This has a bearing as to its accuracy. |
The operations allowed are as described in the CYCPOINTS_CYCLES view.
Contains one row for every row in DEMOG. Each row contains the DEMOG columns and the related CENSUS columns. In those cases where there is a CENSUS row but no related DEMOG row no row exists. Because there is a one-to-one relationship between CENSUS and DEMOG and a DEMOG row always has a related CENSUS row, and because without the CENSUS information it is difficult to tell to which individual the demography note refers , there is little utility in maintaining the DEMOG row without maintaining the related CENSUS row. This view provides a convenient way to maintain the CENSUS/DEMOG combination.
Note
The DEMOG_CENSUS view is very similar to the CENSUS_DEMOG view. It is unclear which is more useful so both exist.
Figure 6.9. Query Defining the DEMOG_CENSUS View
SELECT census.cenid AS cenid
, census.sname AS sname
, census.date AS date
, census.grp AS grp
, census.status AS status
, census.cen AS cen
, demog.reference AS reference
, demog.comment AS comment
FROM census, demog
WHERE census.cenid = demog.cenid;

Table 6.5. Columns in the DEMOG_CENSUS View
| Column | From | Description |
|---|---|---|
| Cenid | CENSUS.Cenid | Unique identifier of the CENSUS row. |
| Sname | CENSUS.Sname | Individual who's location has been recorded. |
| Date | CENSUS.Date | Date of demography note. |
| Grp | CENSUS.Grp | Group where the individual was located. |
| Status | CENSUS.Status | Source of location information. When the source is both a demography note and another source, like a census, the other source is shown. |
| Cen | CENSUS.Cen | Whether or not there was an entry on the field census data sheet for the individual on the given date. |
| Reference | DEMOG.Reference | The group identifying the written field notebook where the demography note can be found. |
| Comment | DEMOG.Comment | The demography note text. |
Inserting a row into DEMOG_CENSUS inserts a row,
into DEMOG, as expected, but only when
the underlying DEMOG columns are not
NULL. If the values of the columns belonging to the
DEMOG table are null then the insert
raises an error.
A new CENSUS row is inserted if
there is not already an existing CENSUS
row, otherwise the existing CENSUS row
is updated. To leave the value of an existing CENSUS row untouched either omit the column
from the insert or specify the NULL value.
Warning
Values must be supplied for either the Cenid or all of the Sname, Date, and Grp columns or else the system will be unable to identify pre-existing CENSUS rows updated by inserts to DEMOG_CENSUS. The system may silently ignore insert operations when too few column values are supplied.
When a new CENSUS row is created the Cen column defaults to false.
Warning
The PostgreSQL nextval()
function cannot be part of an INSERT
expression which assigns a value to this view's Cenid
column.
Updating a row in DEMOG_CENSUS updates the underlying columns in CENSUS and DEMOG, as expected. However, the relationship between CENSUS and DEMOG introduces some complications.
Caution
The CENSUS table is updated before the DEMOG table. Because updating the DEMOG table can change the CENSUS.Status column the resulting value may not be that specified by the update.
Updating the Cenid column updates[248] the Cenid columns in both CENSUS and DEMOG.
Deleting rows from DEMOG_CENSUS updates the database in a fashion that removes the related demography note information from storage.[249]
Deleting a row in DEMOG_CENSUS deletes the
underlying row in CENSUS when
appropriate; when the CENSUS row exists
only because there is an underlying row in DEMOG. That is, the CENSUS
row is deleted if and only if the CENSUS.Cen column is
FALSE. If there is an underlying row in DEMOG it is always deleted.
Note
Regardless of whether the underlying CENSUS row is deleted a delete operation will always cause the deleted row to disappear from the DEMOG_CENSUS view.
Contains one row for every row in the DEMOG_CENSUS view. The only difference between this view and the DEMOG_CENSUS view is that this view is sorted.
Figure 6.11. Query Defining the DEMOG_CENSUS_SORTED View
SELECT census.cenid AS cenid
, census.sname AS sname
, census.date AS date
, census.grp AS grp
, census.status AS status
, census.cen AS cen
, demog.reference AS reference
, demog.comment AS comment
FROM census, demog
WHERE census.cenid = demog.cenid
ORDER BY census.sname, census.date;
Table 6.6. Columns in the DEMOG_CENSUS_SORTED View
| Column | From | Description |
|---|---|---|
| Cenid | CENSUS.Cenid | Unique identifier of the CENSUS row. |
| Sname | CENSUS.Sname | Individual who's location has been recorded. |
| Date | CENSUS.Date | Date of demography note. |
| Grp | CENSUS.Grp | Group where the individual was located. |
| Status | CENSUS.Status | Source of location information. When the source is both a demography note and another source, like a census, the other source is shown. |
| Cen | CENSUS.Cen | Whether or not there was an entry on the field census data sheet for the individual on the given date. |
| Reference | DEMOG.Reference | The group identifying the written field notebook where the demography note can be found. |
| Comment | DEMOG.Comment | The demography note text. |
The operations allowed are as described in the DEMOG_CENSUS view.
Contains one row for every row in the GROUPS table. This view portrays a group's history in a more-accessible format than the GROUPS table. It collects into one row all the dates that are relevant to a particular group, including (in the case of groups that fissioned) the date they became "impermanent" by starting to fission.
This view is similar to GROUPS, but omits columns used predominantly for data entry and validation. This view also renames some columns for clarity, and adds three calculated columns.
Figure 6.13. Query Defining the GROUPS_HISTORY View
SELECT groups.gid AS gid
, groups.name AS name
, groups.from_group AS from_group
, groups.to_group AS to_group
, CASE
WHEN groups.from_group IS NULL
AND NOT EXISTS (SELECT 1
FROM groups AS from_groups
WHERE from_groups.to_group = groups.gid)
THEN groups.permanent
ELSE groups.start
END AS first_observed
, CASE
WHEN groups.study_grp IS NULL
THEN NULL
WHEN groups.from_group IS NULL
AND NOT EXISTS (SELECT 1
FROM groups AS from_groups
WHERE from_groups.to_group = groups.gid)
THEN groups.permanent
ELSE (SELECT date
FROM census
WHERE census.grp = groups.gid
AND census.cen
ORDER BY date
LIMIT 1)
END AS first_study_grp_census
, groups.permanent AS permanent
, (SELECT descgroups_start.start
FROM babase.groups AS descgroups_start
WHERE descgroups_start.from_group = groups.gid
OR descgroups_start.gid = groups.to_group
ORDER BY descgroups_start.start
LIMIT 1
) AS impermanent
, groups.cease_to_exist AS cease_to_exist
, groups.last_reg_census AS last_reg_census
, groups.study_grp
FROM babase.groups;

Table 6.7. Columns in the GROUPS_HISTORY View
| Column | From | Description |
|---|---|---|
| Gid | GROUPS.Gid | Unique identifier of the GROUPS row. |
| Name | GROUPS.Name | Name of this group. |
| From_Group | GROUPS.From_group | The Gid of the group from which this group was created. |
| First_Observed | GROUPS.Permanent, GROUPS.Start | The first date the group was observed. For groups that are fission or fusion products of other known groups, this is the group's Start. Otherwise, this is the group's Permanent. |
| First_Study_Grp_Census | GROUPS.Permanent, CENSUS.Date | The first date that a study group was
observed as its own group and not a subgroup from
its parent group (in the case of fissions) or as a
temporary multi-group encounter (in the case of
fusions). For non-study groups (Study_Grp is NULL), this is
NULL. For groups of unknown lineage (groups whose
From_group is NULL and
whose Gid does not exist as
a To_group)[a], this is the group's Permanent date. Otherwise, this
is the group's earliest CENSUS.Date
where Cen is
TRUE. |
| Permanent | GROUPS.Permanent | The first date on which the group was recognized as its own distinct group. |
| Impermanent | GROUPS.Start | The earliest Start date of this group's fission or fusion products. |
| Cease_To_Exist | GROUPS.Cease_To_Exist | The last date of this group's existence, and the day before fission or fusion products of this group became permanent. |
| Last_Reg_Census | GROUPS.Last_Reg_Census | The date of the last regular census done on the group. |
| Study_Grp | GROUPS.Study_Grp | The date the group became an "official" study
group, or NULL if the group was never a study
group. |
|
[a] Which is expected to only occur when a previously unseen group is first seen and becomes a known group. |
||
Contains one row for every BIOGRAPH
row for which there is either a row in MATERNITIES with a record of the individual's
mother or there is a row in DADS_CONSENSUS
with a record of the individual's father -- where DADS_CONSENSUS.Dad_Consensus is not NULL.
Note
A row in this view can have a NULL Mom or a NULL
Dad, but not both. When there is neither a Mom (i.e., the
offspring has a NULL BIOGRAPH.Pid) nor a Dad (i.e., the offspring has
either a NULL.DADS_CONSENSUS.Dad_Consensus or no related DADS_CONSENSUS data row for the father at all)
the view has no row for the individual.
Figure 6.15. Query Defining the PARENTS View
SELECT biograph.sname AS kid
, maternities.mom AS mom
, dads_consensus.dad_consensus AS dad
, maternities.zdate AS zdate
, maternities.zdate_grp AS momgrp
, members.grp AS dadgrp
FROM biograph
LEFT OUTER JOIN maternities
ON (maternities.child = biograph.sname)
LEFT OUTER JOIN dads_consensus
ON (dads_consensus.kid = biograph.sname)
LEFT OUTER JOIN members
ON (members.sname = dads_consensus.dad_consensus
AND members.date = maternities.zdate)
WHERE maternities.mom IS NOT NULL
OR dads_consensus.dad_consensus IS NOT NULL;

Table 6.8. Columns in the PARENTS View
| Column | From | Description |
|---|---|---|
| Kid | BIOGRAPH.Sname | Identifier (Sname) of the offspring. |
| Mom | CYCLES.Sname | Identifier (Sname)
of the mother, or NULL if the mother is not
known. |
| Dad | DADS_CONSENSUS.Dad_Consensus | Identifier (Sname)
of the father -- the manually chosen
father-of-choice --, or NULL if there is
none. |
| Zdate | CYCPOINTS.Date | Conception date-of-record, or NULL if the
mother is not known. |
| Momgrp | MEMBERS.Grp | Mother's group as of the conception
date-of-record, or NULL if the mother is not
known. |
| Dadgrp | MEMBERS.Grp | The group of the father on the Zdate, or
NULL if there is either no consensus dad or the
Zdate is not known. |
Contains one row for every (completed) female reproductive event for every male more than 2192 days old (approximately 6 years) present in the mother's supergroup during her fertile period. So, one row for every potential dad of every birth and fetal loss. The Potential_Dads-Status column can be used to distinguish males that are adult on the Zdate from subadults from males that have no record of testicular enlargement -- the males having no MATUREDATES.Matured.
Figure 6.17. Query Defining the POTENTIAL_DADS View
SELECT maternities.child_bioid AS bioid
, maternities.child AS kid
, maternities.mom AS mom
, maternities.zdate AS zdate
, maternities.zdate_grp AS grp
, pdads.sname AS pdad
, CASE
WHEN rankdates.ranked <= maternities.zdate
THEN 'A'
WHEN maturedates.matured <= maternities.zdate
THEN 'S'
ELSE 'O'
END
AS status
, maternities.zdate - pdads.birth AS pdad_age_days
, trunc((maternities.zdate - pdads.birth) / 365.25, 1)
AS pdad_age_years
, (SELECT count(*)
FROM members as dadmembers
JOIN members AS mommembers
ON (mommembers.date = dadmembers.date
AND mommembers.supergroup = dadmembers.supergroup)
WHERE dadmembers.sname = pdads.sname
AND dadmembers.date < maternities.zdate
AND dadmembers.date >= maternities.zdate - 5
AND mommembers.sname = maternities.mom
AND mommembers.date < maternities.zdate
AND mommembers.date >= maternities.zdate - 5)
AS estrous_presence
, (SELECT count(*)
FROM actor_actees
WHERE actor_actees.date < maternities.zdate
AND actor_actees.date >= maternities.zdate - 5
AND (actor_actees.act = 'M'
OR actor_actees.act = 'E')
AND actor_actees.actor = pdads.sname
AND actor_actees.actee = maternities.mom)
AS estrous_me
, (SELECT count(*)
FROM actor_actees
WHERE actor_actees.date < maternities.zdate
AND actor_actees.date >= maternities.zdate - 5
AND actor_actees.act = 'C'
AND actor_actees.actor = pdads.sname
AND actor_actees.actee = maternities.mom)
AS estrous_c
FROM maternities
JOIN biograph AS pdads
ON (pdads.sname
IN (SELECT dadmembers.sname
FROM members AS dadmembers
JOIN members AS mommembers
ON (mommembers.date = dadmembers.date
AND mommembers.supergroup
= dadmembers.supergroup)
WHERE dadmembers.sname = pdads.sname
AND dadmembers.date < maternities.zdate
AND dadmembers.date >= maternities.zdate - 5
AND mommembers.sname = maternities.mom
AND mommembers.date < maternities.zdate
AND mommembers.date >= maternities.zdate - 5))
LEFT OUTER JOIN rankdates
ON (rankdates.sname = pdads.sname)
LEFT OUTER JOIN maturedates
ON (maturedates.sname = pdads.sname)
WHERE pdads.sex = 'M'
-- Speed things up by eliminating potential dads
-- who could not possibly interpolate into the mom's group
-- during the fertile period.
AND pdads.statdate >= maternities.zdate - 5 - 14
-- Potential dad must be at least 2192 days old
-- (approximately 6 years) on the zdate.
AND maternities.zdate - pdads.birth >= 2192;

Figure 6.19. Entity Relationship Diagram of that portion of the POTENTIAL_DADS View which places the mother and potential father in the same group during the fertile period

|
Figure 6.20. Entity Relationship Diagram of that portion of the POTENTIAL_DADS View having easily computed columns

|
Figure 6.21. Entity Relationship Diagram of that portion of the POTENTIAL_DADS View involving social interactions
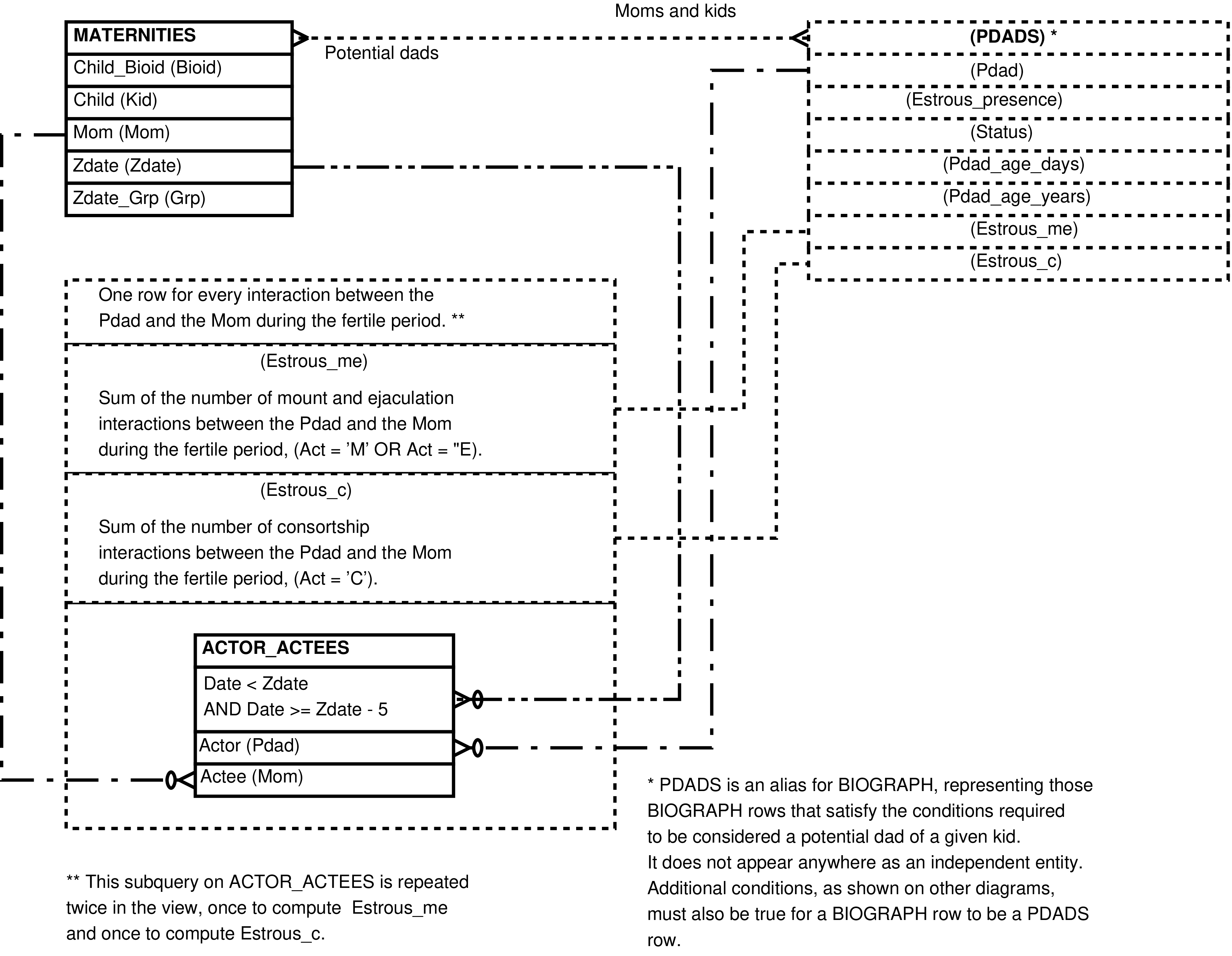
|
Table 6.9. Columns in the POTENTIAL_DADS View
| Column | From | Description |
|---|---|---|
| Bioid | BIOGRAPH.Bioid | Numeric identifier (Bioid) of the offspring. |
| Kid | BIOGRAPH.Sname | Identifier (Sname) of the offspring. |
| Mom | CYCLES.Sname | Identifier (Sname) of the mother. |
| Zdate | CYCPOINTS.Date | Conception date-of-record. |
| Zdate_Grp | MEMBERS.Grp | Mother's group as of the conception date-of-record. |
| Pdad | BIOGRAPH.Sname | Identifier (Sname) of the potential father. |
| Status |
|
The maturity of the potential dad as of the
Zdate, as follows:
POTENTIAL_DADS.Status values
|
| Pdad_age_days | Zdate - BIOGRAPH.Birth | The age, in days, of the potential dad as of the Zdate -- the Zdate minus the potential dad's BIOGRAPH.Birth. |
| Pdad_age_years | Pdad_age_days / 365.25 | The age, in years, of the potential dad as of the Zdate. |
| Estrous_presence | Subquery on MEMBERS -- see Figure 6.19. | Count of the number of days the potential dad is in the same supergroup as the supergroup of the mother during the mother's fertile period -- the 5 days prior to the Zdate. |
| Estrous_me | Subquery on ACTOR_ACTEES -- see Figure 6.21. | Sum of the number of mounts and ejaculation interactions between the Mom and the Pdad during the fertile period -- the 5 days prior to the Zdate. |
| Estrous_c | Subquery on ACTOR_ACTEES -- see Figure 6.21. | Sum of the number of consortship interactions between the Mom and the Pdad during the fertile period -- the 5 days prior to the Zdate. |
Contains one row for every row in RANKS. Each row contains all the columns from RANKS and an additional column with the calculated proportional rank.
Proportional rank is a method of ranking that accounts
for the size of the group[250]. Its values should extend between
0 (low rank) and 1 (high
rank), and can be interpreted as "the percent of the group over
which this individual is dominant".
Caution
Be careful when comparing ordinal and proportional rank
values to each other. Ordinal ranks (from RANKS) begin at 1 (high rank),
with ascending values indicating lower rank. Proportional
ranks go in the reverse direction: as proportional rank
values ascend, these values indicate higher ranks.
Figure 6.22. Query Defining the PROPORTIONAL_RANKS View
WITH num_indivs AS (
SELECT ranks.rnkdate
, ranks.grp
, ranks.rnktype
, count(*) AS num_members
FROM ranks
GROUP BY ranks.rnkdate, ranks.grp, ranks.rnktype)
SELECT ranks.rnkid AS rnkid
, ranks.sname AS sname
, ranks.rnkdate AS rnkdate
, ranks.grp AS grp
, ranks.rnktype AS rnktype
, ranks.rank AS ordrank
, ranks.ags_density AS ags_density
, ranks.ags_reversals AS ags_reversals
, ranks.ags_expected AS ags_expected
, CASE
WHEN num_indivs.num_members = 1 THEN 1::numeric
ELSE 1 - ((ranks.rank - 1)::numeric / (num_indivs.num_members - 1)::numeric)
END::numeric(5,4) AS proprank
FROM ranks
JOIN num_indivs
ON (num_indivs.rnkdate = ranks.rnkdate
AND num_indivs.grp = ranks.grp
AND num_indivs.rnktype = ranks.rnktype);
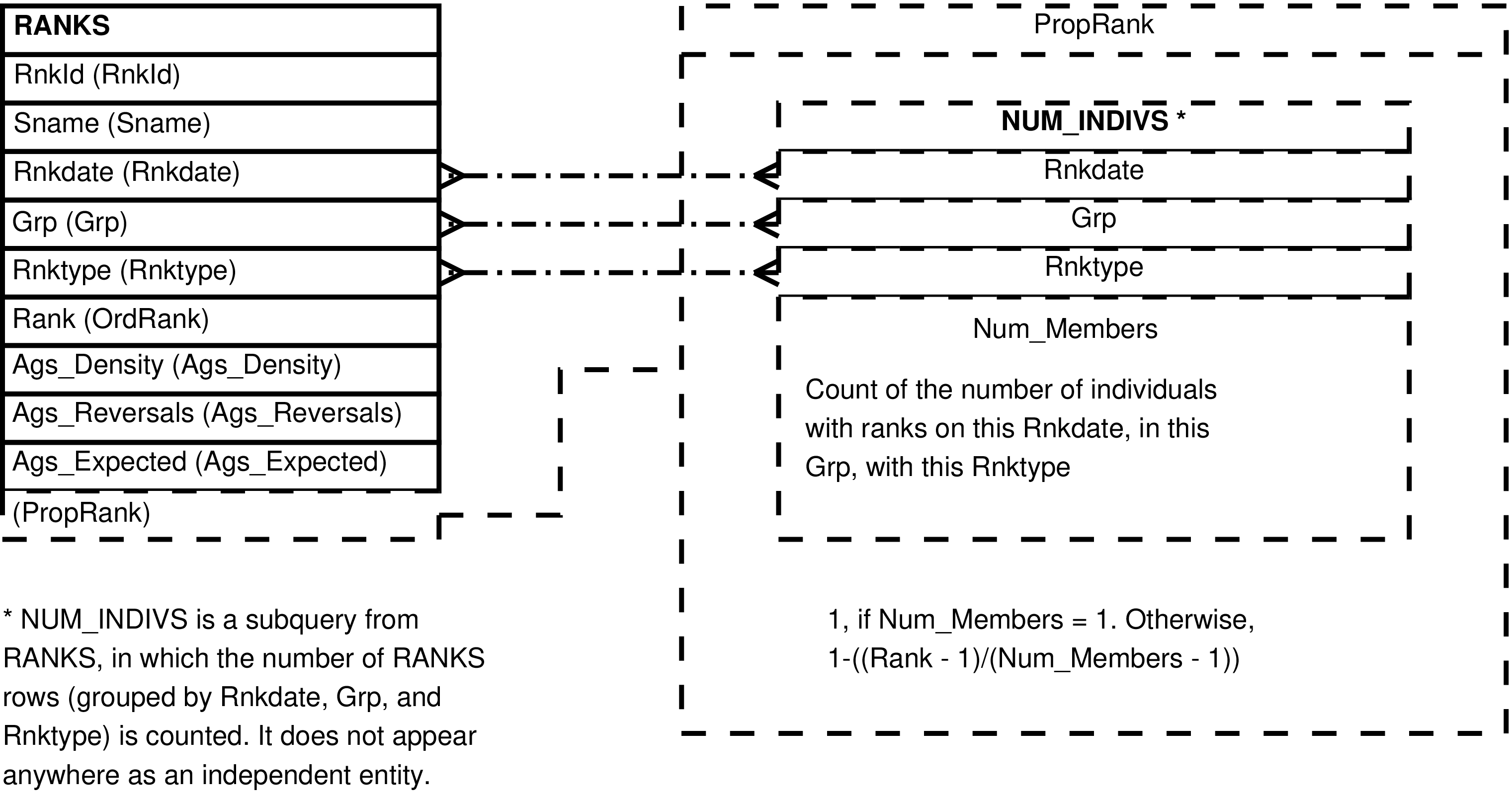
Table 6.10. Columns in the PROPORTIONAL_RANKS View
| Column | From | Description |
|---|---|---|
| RnkId | RANKS.Rnkid | Unique identifier of the RANKS row. |
| Sname | RANKS.Sname | Sname of the ranked individual. |
| Rnkdate | RANKS.Rnkdate | The date indicating the year and month of this ranking. |
| Grp | RANKS.Grp | The group in which this individual is ranked. |
| Rnktype | RANKS.Rnktype | The kind of rank assigned to this individual. |
| OrdRank | RANKS.Rank | The ordinal rank assigned to this individual. |
| PropRank |
|
The calculated proportional rank for this individual. Expressed as a value between 0 (low rank) and 1 (high rank), inclusive. |